Definition of Process
Basically, a process is a simple program.
An active program which running now on the Operating System is known as the process. The Process is the base of all computing things. Although process is relatively similar to the computer code but, the method is not the same as computer code. A process is a "active" entity, in contrast to the program, which is sometimes thought of as some sort of "passive" entity. The properties that the process holds include the state of the hardware, the RAM, the CPU, and other attributes.
Process in an Operating System
A process is actively running software or a computer code. Any procedure must be carried out in a precise order. An entity that helps in describing the fundamental work unit that must be implemented in any system is referred to as a process.
In other words, we create computer programs as text files that, when executed, create processes that carry out all of the tasks listed in the program.
When a program is loaded into memory, it may be divided into the four components stack, heap, text, and data to form a process. The simplified depiction of a process in the main memory is shown in the diagram below.
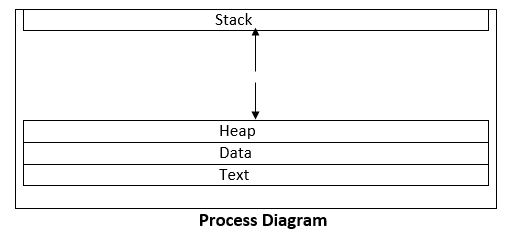
Stack
The process stack stores temporary information such as method or function arguments, the return address, and local variables.
Heap
This is the memory where a process is dynamically allotted while it is running.
Text
This consists of the information stored in the processor's registers as well as the most recent activity indicated by the program counter's value.
Data
In this section, both global and static variables are discussed.
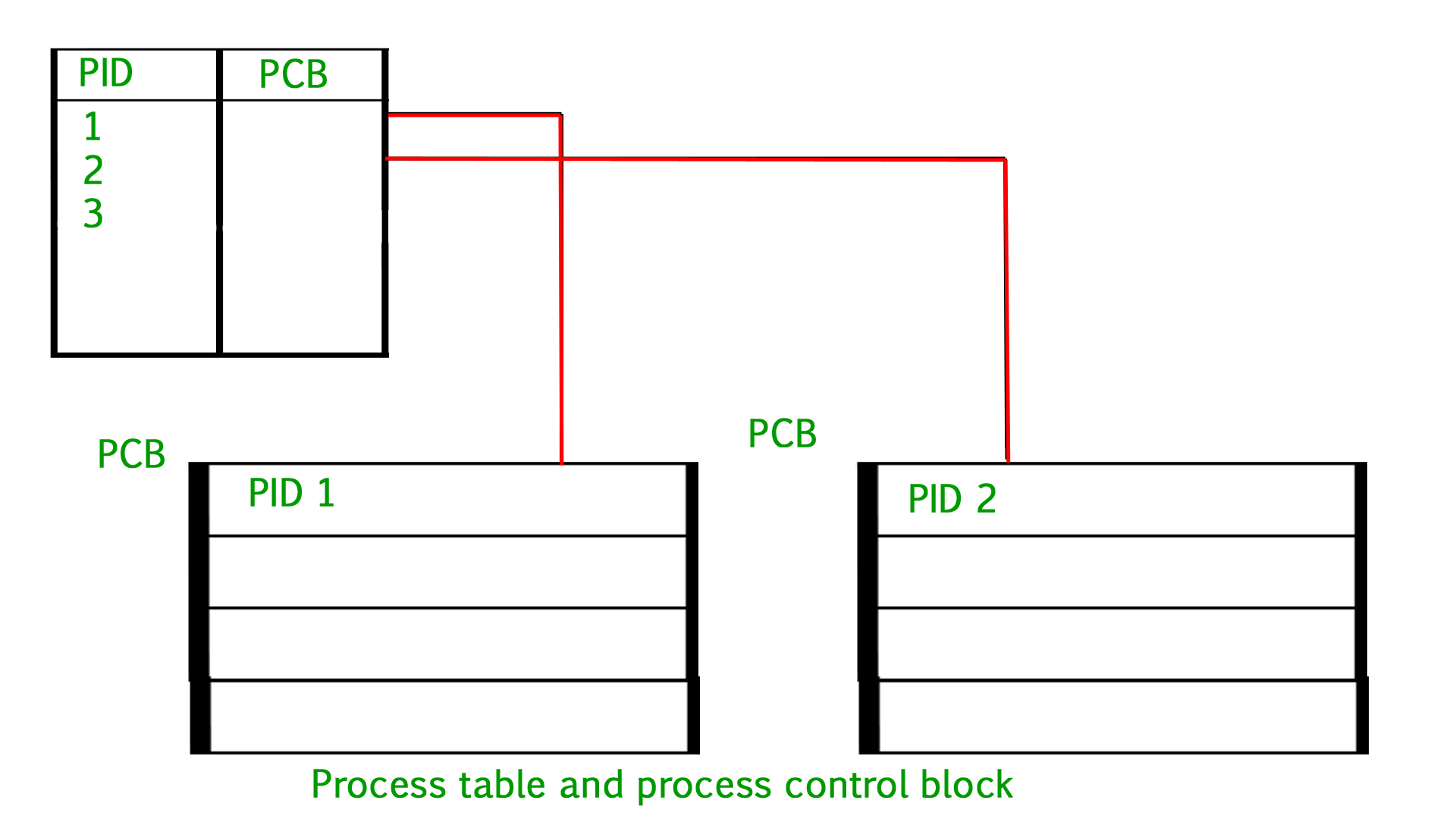
Process Table and Process Control Block (PCB)
While creating a process, the operating system performs several operations. To identify the processes, it assigns a process identification number (PID) to each process. As the operating system supports multi-programming, it needs to keep track of all the processes. For this task, the process control block (PCB) is used to track the process’s execution status. Each block of memory contains information about the process state, program counter, stack pointer, status of opened files, scheduling algorithms, etc.
All this information is required and must be saved when the process is switched from one state to another. When the process makes a transition from one state to another, the operating system must update information in the process’s PCB. A process control block (PCB) contains information about the process, i.e. registers, quantum, priority, etc. The process table is an array of PCBs, that means logically contains a PCB for all of the current processes in the system.

- *Pointer:* It is a stack pointer that is required to be saved when the process is switched from one state to another to retain the current position of the process.
- *Process state:* It stores the respective state of the process.
- *Process number:* Every process is assigned a unique id known as process ID or PID which stores the process identifier.
- *Program counter: It stores the counter,:* which contains the address of the next instruction that is to be executed for the process.
- *Register:* These are the CPU register which include the accumulator, base, registers, and general-purpose registers.
- *Memory limits:* This field contains the information about memory management system used by the operating system. This may include page tables, segment tables, etc.
- *Open files list :* This information includes the list of files opened for a process.
*Additional Points to Consider for Process Control Block (PCB)*
- *Interrupt handling:* The PCB also contains information about the interrupts that a process may have generated and how they were handled by the operating system.
- *Context switching:* The process of switching from one process to another is called context switching. The PCB plays a crucial role in context switching by saving the state of the current process and restoring the state of the next process.
- *Real-time systems:* Real-time operating systems may require additional information in the PCB, such as deadlines and priorities, to ensure that time-critical processes are executed in a timely manner.
- *Virtual memory management:* The PCB may contain information about a process’s virtual memory management, such as page tables and page fault handling.
- *Inter-process communication:* The PCB can be used to facilitate inter-process communication by storing information about shared resources and communication channels between processes.
- *Fault tolerance:* Some operating systems may use multiple copies of the PCB to provide fault tolerance in case of hardware failures or software errors.
Advantages-
- *Efficient process management:* The process table and PCB provide an efficient way to manage processes in an operating system. The process table contains all the information about each process, while the PCB contains the current state of the process, such as the program counter and CPU registers.
- *Resource management:* The process table and PCB allow the operating system to manage system resources, such as memory and CPU time, efficiently. By keeping track of each process’s resource usage, the operating system can ensure that all processes have access to the resources they need.
- *Process synchronization:* The process table and PCB can be used to synchronize processes in an operating system. The PCB contains information about each process’s synchronization state, such as its waiting status and the resources it is waiting for.
- *Process scheduling:* The process table and PCB can be used to schedule processes for execution. By keeping track of each process’s state and resource usage, the operating system can determine which processes should be executed next.
Disadvantages-
- *Overhead:* The process table and PCB can introduce overhead and reduce system performance. The operating system must maintain the process table and PCB for each process, which can consume system resources.
- *Complexity:* The process table and PCB can increase system complexity and make it more challenging to develop and maintain operating systems. The need to manage and synchronize multiple processes can make it more difficult to design and implement system features and ensure system stability.
- *Scalability:* The process table and PCB may not scale well for large-scale systems with many processes. As the number of processes increases, the process table and PCB can become larger and more difficult to manage efficiently.
- *Security:* The process table and PCB can introduce security risks if they are not implemented correctly. Malicious programs can potentially access or modify the process table and PCB to gain unauthorized access to system resources or cause system instability.
- *Miscellaneous accounting and status data –* This field includes information about the amount of CPU used, time constraints, jobs or process number, etc. The process control block stores the register content also known as execution content of the processor when it was blocked from running. This execution content architecture enables the operating system to restore a process’s execution context when the process returns to the running state. When the process makes a transition from one state to another, the operating system updates its information in the process’s PCB. The operating system maintains pointers to each process’s PCB in a process table so that it can access the PCB quickly.
Different Types of Process Schedulers
Process Scheduling handles the selection of a process for the processor on the basis of a scheduling algorithm and also the removal of a process from the processor. It is an important part of multiprogramming operating system.
There are many scheduling queues that are used in process scheduling. When the processes enter the system, they are put into the job queue. The processes that are ready to execute in the main memory are kept in the ready queue. The processes that are waiting for the I/O device are kept in the I/O device queue.
The different schedulers that are used for process scheduling are −
Long Term Scheduler
The job scheduler or long-term scheduler selects processes from the storage pool in the secondary memory and loads them into the ready queue in the main memory for execution.
The long-term scheduler controls the degree of multiprogramming. It must select a careful mixture of I/O bound and CPU bound processes to yield optimum system throughput. If it selects too many CPU bound processes then the I/O devices are idle and if it selects too many I/O bound processes then the processor has nothing to do.
The job of the long-term scheduler is very important and directly affects the system for a long time.
Short Term Scheduler
The short-term scheduler selects one of the processes from the ready queue and schedules them for execution. A scheduling algorithm is used to decide which process will be scheduled for execution next.
The short-term scheduler executes much more frequently than the long-term scheduler as a process may execute only for a few milliseconds.
The choices of the short term scheduler are very important. If it selects a process with a long burst time, then all the processes after that will have to wait for a long time in the ready queue. This is known as starvation and it may happen if a wrong decision is made by the short-term scheduler.
A diagram that demonstrates long-term and short-term schedulers is given as follows −
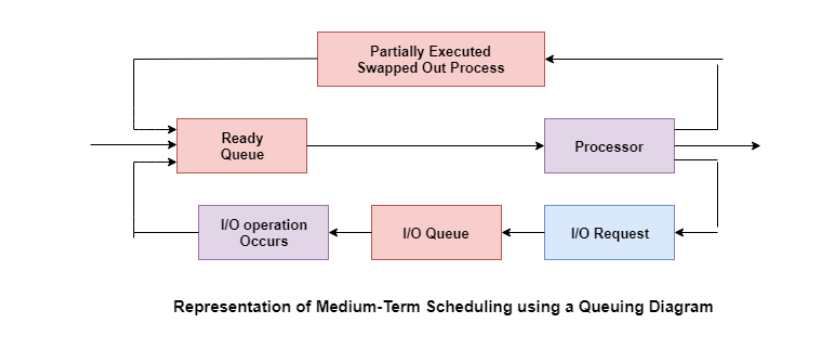
Medium Term Scheduler
The medium-term scheduler swaps out a process from main memory. It can again swap in the process later from the point it stopped executing. This can also be called as suspending and resuming the process.
This is helpful in reducing the degree of multiprogramming. Swapping is also useful to improve the mix of I/O bound and CPU bound processes in the memory.
A diagram that demonstrates medium-term scheduling is given as follows −
Context Switching in OS (Operating System)
The Context switching is a technique or method used by the operating system to switch a process from one state to another to execute its function using CPUs in the system. When switching perform in the system, it stores the old running process's status in the form of registers and assigns the CPU to a new process to execute its tasks. While a new process is running in the system, the previous process must wait in a ready queue. The execution of the old process starts at that point where another process stopped it. It defines the characteristics of a multitasking operating system in which multiple processes shared the same CPU to perform multiple tasks without the need for additional processors in the system.
The need for Context switching
A context switching helps to share a single CPU across all processes to complete its execution and store the system's tasks status. When the process reloads in the system, the execution of the process starts at the same point where there is conflicting.
Following are the reasons that describe the need for context switching in the Operating system.
- The switching of one process to another process is not directly in the system. A context switching helps the operating system that switches between the multiple processes to use the CPU's resource to accomplish its tasks and store its context. We can resume the service of the process at the same point later. If we do not store the currently running process's data or context, the stored data may be lost while switching between processes.
- If a high priority process falls into the ready queue, the currently running process will be shut down or stopped by a high priority process to complete its tasks in the system.
- If any running process requires I/O resources in the system, the current process will be switched by another process to use the CPUs. And when the I/O requirement is met, the old process goes into a ready state to wait for its execution in the CPU. Context switching stores the state of the process to resume its tasks in an operating system. Otherwise, the process needs to restart its execution from the initials level.
- If any interrupts occur while running a process in the operating system, the process status is saved as registers using context switching. After resolving the interrupts, the process switches from a wait state to a ready state to resume its execution at the same point later, where the operating system interrupted occurs.
- A context switching allows a single CPU to handle multiple process requests simultaneously without the need for any additional processors.
Steps for Context Switching
There are several steps involves in context switching of the processes. The following diagram represents the context switching of two processes, P1 to P2, when an interrupt, I/O needs, or priority-based process occurs in the ready queue of PCB.
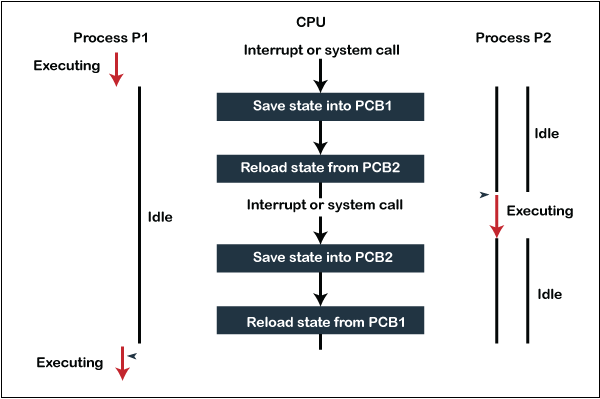
As we can see in the diagram, initially, the P1 process is running on the CPU to execute its task, and at the same time, another process, P2, is in the ready state. If an error or interruption has occurred or the process requires input/output, the P1 process switches its state from running to the waiting state. Before changing the state of the process P1, context switching saves the context of the process P1 in the form of registers and the program counter to the PCB1. After that, it loads the state of the P2 process from the ready state of the PCB2 to the running state.
The following steps are taken when switching Process P1 to Process 2:
- First, thes context switching needs to save the state of process P1 in the form of the program counter and the registers to the PCB (Program Counter Block), which is in the running state.
- Now update PCB1 to process P1 and moves the process to the appropriate queue, such as the ready queue, I/O queue and waiting queue.
- After that, another process gets into the running state, or we can select a new process from the ready state, which is to be executed, or the process has a high priority to execute its task.
- Now, we have to update the PCB (Process Control Block) for the selected process P2. It includes switching the process state from ready to running state or from another state like blocked, exit, or suspend.
- If the CPU already executes process P2, we need to get the status of process P2 to resume its execution at the same time point where the system interrupt occurs.
Similarly, process P2 is switched off from the CPU so that the process P1 can resume execution. P1 process is reloaded from PCB1 to the running state to resume its task at the same point. Otherwise, the information is lost, and when the process is executed again, it starts execution at the initial level.
Thread in Operating System
Within a program, a *Thread* is a separate execution path. It is a lightweight process that the operating system can schedule and run concurrently with other threads. The operating system creates and manages threads, and they share the same memory and resources as the program that created them. This enables multiple threads to collaborate and work efficiently within a single program.
A thread is a single sequence stream within a process. Threads are also called lightweight processes as they possess some of the properties of processes. Each thread belongs to exactly one process. In an operating system that supports multithreading, the process can consist of many threads. But threads can be effective only if CPU is more than 1 otherwise two threads have to context switch for that single CPU.
Why Do We Need Thread?
- Threads run in parallel improving the application performance. Each such thread has its own CPU state and stack, but they share the address space of the process and the environment.
- Threads can share common data so they do not need to use interprocess communication. Like the processes, threads also have states like ready, executing, blocked, etc.
- Priority can be assigned to the threads just like the process, and the highest priority thread is scheduled first.
- Each thread has its own Thread Control Block (TCB). Like the process, a context switch occurs for the thread, and register contents are saved in (TCB). As threads share the same address space and resources, synchronization is also required for the various activities of the thread.
Multi-Threading Models
Multithreading allows the execution of multiple parts of a program at the same time. These parts are known as threads and are lightweight processes available within the process. Therefore, multithreading leads to maximum utilization of the CPU by multitasking.
The main models for multithreading are one to one model, many to one model and many to many model. Details about these are given as follows −
One to One Model
The one to one model maps each of the user threads to a kernel thread. This means that many threads can run in parallel on multiprocessors and other threads can run when one thread makes a blocking system call.
A disadvantage of the one to one model is that the creation of a user thread requires a corresponding kernel thread. Since a lot of kernel threads burden the system, there is restriction on the number of threads in the system.
A diagram that demonstrates the one to one model is given as follows −

Many to One Model
The many to one model maps many of the user threads to a single kernel thread. This model is quite efficient as the user space manages the thread management.
A disadvantage of the many to one model is that a thread blocking system call blocks the entire process. Also, multiple threads cannot run in parallel as only one thread can access the kernel at a time.
A diagram that demonstrates the many to one model is given as follows −

Many to Many Model
The many to many model maps many of the user threads to a equal number or lesser kernel threads. The number of kernel threads depends on the application or machine.
The many to many does not have the disadvantages of the one to one model or the many to one model. There can be as many user threads as required and their corresponding kernel threads can run in parallel on a multiprocessor.
A diagram that demonstrates the many to many model is given as follows −

Goals of scheduling
The scheduling of processes in an operating system is a critical function that aims to achieve several goals to ensure efficient and effective utilization of system resources. The primary goals of scheduling in an operating system include:
- Maximizing CPU Utilization:
- The primary goal is to keep the CPU as busy as possible to ensure high system throughput.
-
Idle CPU time represents wasted resources, and efficient scheduling aims to minimize the idle time.
-
Fairness:
- Scheduling should be fair to all processes, ensuring that no process is unfairly starved of CPU time.
-
Fairness is essential to prevent certain processes from monopolizing system resources.
-
Minimizing Turnaround Time:
- Turnaround time is the total time taken to execute a process, including waiting time and execution time.
-
Scheduling algorithms aim to minimize turnaround time to improve the overall system performance.
-
Minimizing Waiting Time:
- Waiting time is the time a process spends waiting in the ready queue before it gets CPU time.
-
Scheduling algorithms strive to minimize waiting time to enhance system responsiveness.
-
Minimizing Response Time:
- Response time is the time it takes for the system to respond to a user request or an event.
-
Scheduling algorithms target minimizing response time to provide a more interactive and responsive user experience.
-
Maximizing Throughput:
- Throughput is a measure of the number of processes that can be completed in a unit of time.
-
Scheduling aims to maximize throughput to ensure efficient use of system resources.
-
Ensuring Deadlines and Priorities:
-
In real-time systems, meeting deadlines is crucial. Scheduling must consider task priorities and deadlines to ensure timely execution of critical tasks.
-
Balancing Resource Utilization:
-
Scheduling should aim to balance the utilization of various system resources, such as CPU, memory, and I/O devices, to prevent bottlenecks.
-
Adaptability and Responsiveness:
- Scheduling algorithms should be adaptive to varying workloads and responsive to changes in the system environment.
-
Dynamic scheduling strategies adjust to workload changes to optimize system performance.
-
Energy Efficiency:
- In mobile and battery-powered devices, scheduling algorithms may aim to minimize energy consumption by efficiently managing power states and transitions.
-
Minimizing Starvation:
- Starvation occurs when a process is unable to get CPU time for an extended period. Scheduling aims to prevent starvation and ensure all processes get a fair share of resources.
-
Load Balancing:
- Load balancing involves distributing processes evenly across multiple processors or cores to prevent overloading some resources while leaving others underutilized.
By achieving these goals, the scheduling component of an operating system plays a crucial role in optimizing the overall system performance and ensuring a responsive and efficient computing environment. Different scheduling algorithms may be employed based on the specific requirements and characteristics of the system.
Scheduling Algorithms in OS (Operating System)
There are various algorithms which are used by the Operating System to schedule the processes on the processor in an efficient way.
The Purpose of a Scheduling algorithm
- Maximum CPU utilization
- Fare allocation of CPU
- Maximum throughput
- Minimum turnaround time
- Minimum waiting time
- Minimum response time
There are the following algorithms which can be used to schedule the jobs.
1. First Come First Serve
It is the simplest algorithm to implement. The process with the minimal arrival time will get the CPU first. The lesser the arrival time, the sooner will the process gets the CPU. It is the non-preemptive type of scheduling.
2. Round Robin
In the Round Robin scheduling algorithm, the OS defines a time quantum (slice). All the processes will get executed in the cyclic way. Each of the process will get the CPU for a small amount of time (called time quantum) and then get back to the ready queue to wait for its next turn. It is a preemptive type of scheduling.
3. Shortest Job First
The job with the shortest burst time will get the CPU first. The lesser the burst time, the sooner will the process get the CPU. It is the non-preemptive type of scheduling.
4. Shortest remaining time first
It is the preemptive form of SJF. In this algorithm, the OS schedules the Job according to the remaining time of the execution.
5. Priority based scheduling
In this algorithm, the priority will be assigned to each of the processes. The higher the priority, the sooner will the process get the CPU. If the priority of the two processes is same then they will be scheduled according to their arrival time.
6. Highest Response Ratio Next
In this scheduling Algorithm, the process with highest response ratio will be scheduled next. This reduces the starvation in the system.
References
https://www.javatpoint.com/what-is-the-process-in-operating-system https://www.geeksforgeeks.org/process-table-and-process-control-block-pcb/ https://www.tutorialspoint.com/different-types-of-process-schedulers https://www.javatpoint.com/what-is-the-context-switching-in-the-operating-system https://www.geeksforgeeks.org/thread-in-operating-system/ https://www.tutorialspoint.com/multi-threading-models https://www.javatpoint.com/os-scheduling-algorithms